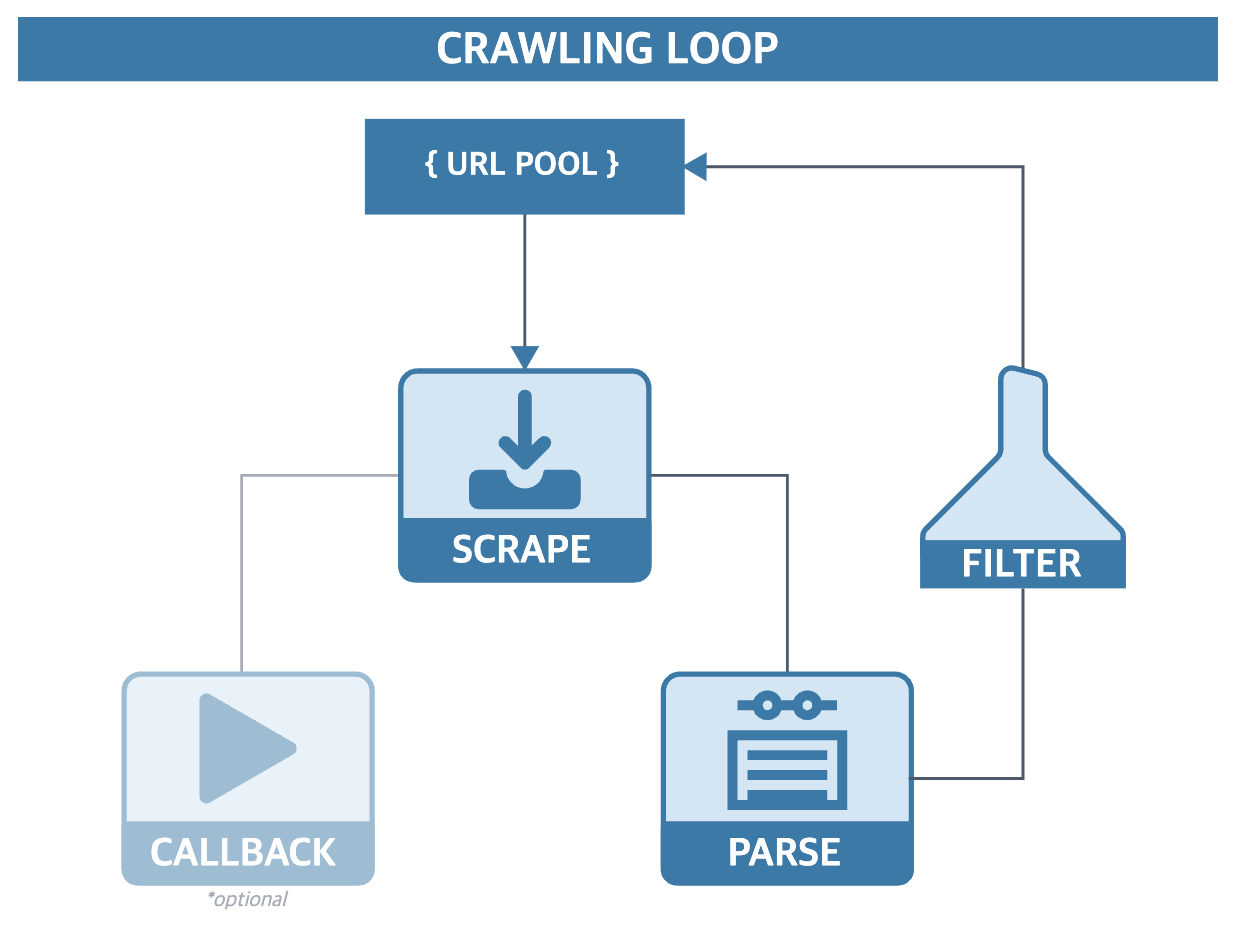
Introduction
최근에 진행한 Project 중 특정 홈페이지를 크롤링하여 파싱하는 프로젝트가 있었습니다. 크롤링 보단 파싱에서 애를 많이 먹었습니다. 문서에서 table을 처리하는 것이 쉽지 않기 때문입니다.
[이번 프로젝트 중점 사항]
- iframe이 존재하는 홈페이지 크롤링
- hwp, xlsx, pdf 파일에서 table(표) 파싱 처리
[주요 python package]
- selenium : 크롤링의 시작과 끝
- olefile : hwp 파일 파싱
- openpyxl : xlsx 파일 파싱
- PyPDF2 : PDF 파일 파싱
iframe 존재하는 홈페이지 크롤링
iframe이 존재하는 경우 창간 전환이 필요합니다. 쉽게 생각하면 브라우저 안에 또다른 창이 있다고 생각하시면 되겠습니다.
from selenium import webdriver
# 드라이버 설정 및 start
driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()), options=options
)
url = "https://www.hscity.go.kr/www/link/BD_notice.do"
driver.get(url)
# iframe 이동
if_notice = driver.find_element(By.ID, "if_notice")
driver.switch_to.frame(if_notice)
이후 원하는 정보를 크롤링 하면 됩니다.
다양한 확장자 파일 파싱
파싱할 때 text에서 정보를 얻는 것과 table에서 정보를 얻는 것 두가지 모두 필요하다고 생각했습니다. 그 중 특히 table에서 정보를 얻는 것을 처리하는 방법이 파일 확장자마다 조금 씩 달랐습니다.
1. HWP(한글) 파일 파싱
olefile을 통해 encoding된 text를 불러오고 decoding 하면 파일 안에 존재하는 table은 <내용><내용><\rn><\rn><내용><내용> 형식으로 이루어져 있습니다. (2x2 table) 그리고 중요한 것이 제가 원하는 내용이 들어간 columndmf 찾는 것인데, 가끔 표를 보면 두줄로 column이 이루어진 경우가 있습니다. 그런 경우 비어있는 column을 다른 줄의 column으로 채워주는 방법을 사용 했습니다.
그러한 특징을 이용한 파싱 코드 입니다.
import olefile
f = olefile.OleFileIO(row["파일경로"])
# PrvText 스트림 내의 내용을 읽기
try:
encoded_text = f.openstream("PrvText").read()
except:
continue # hwp 서식으로 인해 encoding error.
decoded_texts = encoded_text.decode("UTF-16")
texts = decoded_texts.split("<")
cols_num = 0
fixed_cols_num = 0
for text in texts:
if (text.endswith(" ")) | (text == ""):
continue
else:
if text[-2:] == "\r\n":
row.append(text.replace("\r\n", "").split(">")[0])
cols_num += 1
for c in row:
if c in jibun_str_lst:
is_col_nm_row = True
is_start = True
if is_col_nm_row == True:
if col_nms == []:
col_nms = row
else:
# 2중 column row 처리
if len(row) == len(col_nms):
for i in range(len(row)):
if row[i] != None:
col_nms[i] = row[i]
# 길이가 다르면 update
else:
col_nms = row
table_texts = []
fixed_cols_num = cols_num
elif (
(is_start == True)
& (is_col_nm_row == False)
& (cols_num == fixed_cols_num)
):
table_texts.append(row)
row = []
cols_num = 0
is_col_nm_row = False
else:
row.append(text.split(">")[0])
cols_num += 1
if (
(text == texts[-1])
& (cols_num == fixed_cols_num)
& (is_start == True)
):
table_texts.append(row)
2. XLSX(엑셀) 파일 파싱
엑셀을 실질적으로 모두 table입니다. 행과 열 정보를 가져와서 hwp와 동일한 방식으로 파싱하면 됩니다.
from openpyxl import load_workbook
try:
wb = load_workbook(row["파일경로"])
except:
continue # 파싱 불가능한 excel 파일이 있고, Window에서는 동작
# 시트 선택
sheet = wb.active
texts = ""
# 시트에서 데이터 읽기
for r in sheet.iter_rows(values_only=True):
for c in r:
if c != None:
texts += f"{c} "
for r in texts.iter_rows(values_only=True):
# row 생성
for c in r:
if c != None:
c = str(c).strip()
row.append(c)
if c in jibun_lst:
is_col_nm_row = True
is_start = True
# col 관련 정보라면
if is_col_nm_row == True:
if col_nms == []:
col_nms = row
else:
for i in range(len(row)):
if row[i] != None:
col_nms[i] = row[i]
if is_start & (not is_col_nm_row):
table_texts.append(row)
row = []
is_col_nm_row = False
Conclusion
크롤링은 많이 진행해 봤었지만, 실제 문서 파일을 파싱해본 적은 없어서 쉽지 않았습니다. 각 문서에 맞는 파싱 방법을 적용하면 text 뿐 만 아니라 table까지 파싱할 수 있습니다.